W świecie frontendu nie brakuje narzędzi i frameworków. Jednym z najpopularniejszych obecnie zestawów jest trio: React, Tailwind CSS i Vite. To nowoczesne podejście do budowy interfejsów użytkownika, które może znacznie przyspieszyć proces tworzenia aplikacji, o ile wszystko pójdzie zgodnie z planem…
Czym są te technologie?
React to biblioteka JavaScript stworzona przez Facebooka do budowy dynamicznych interfejsów użytkownika. Jej główną zaletą jest komponentowa architektura i ogromna społeczność.
Tailwind CSS to narzędzie do stylowania z podejściem „utility-first”. Zamiast pisać własne klasy CSS, korzystamy z gotowych, deklaratywnych klas bezpośrednio w znacznikach HTML/JSX.
Vite jest lekkim i superszybkim bundlerem stworzonym przez twórcę Vue.js. Działa błyskawicznie dzięki wykorzystaniu ESM i natywnego środowiska przeglądarki, co sprawia, że idealnie nadaje się do developmentu.
Gdzie sprawdzają się najlepiej?
Ten zestaw technologii świetnie sprawdzi się w:
Aplikacjach typu SPA (Single Page Application),
Panelach administracyjnych i dashboardach,
Prototypach i MVP do szybkiego testowania pomysłów,
Landing page’ach – stylowane z użyciem Tailwinda potrafią być imponująco lekkie i nowoczesne,
Projektach edukacyjnych i komponentowych, gdzie są idealne do nauki i dzielenia się komponentami.
W porównaniu z alternatywami (np. Angular + SCSS + Webpack), ten stack oferuje mniejszy narzut, szybszy czas startu i łatwiejszą iterację.
A czy my w ogóle używamy Node.js?
Tak i to całkiem intensywnie, choć pośrednio. Nie budujemy backendu w Node.js, ale całe środowisko narzędziowe Reacta, Vite i Tailwinda opiera się na Node.js. To znaczy:
uruchomienie vite dev startuje lokalny serwer Node.js,
instalacja zależności (npm install, yarn, pnpm) opiera się na Node.js i jego ekosystemie,
Tailwind CSS generuje style przy pomocy narzędzi CLI Node.js.
Dlatego niezgodności wersji node i npm, zbyt stary interpreter czy problematyczna instalacja globalnych paczek potrafią skutecznie zablokować pracę, mimo że „tworzymy tylko prostą stronę w React”.
Dlaczego używamy WSL?
Na pierwszy rzut oka może wydawać się, że wszystko powinno działać równie dobrze na Windowsie. Niestety, tak nie jest. Różnice w środowisku, zarządzaniu pakietami i narzędziach systemowych potrafią być źródłem trudnych do zdiagnozowania błędów.
WSL (Windows Subsystem for Linux) pozwala nam pracować w przewidywalnym, zgodnym z ekosystemem Linuksa środowisku, czyli takim, jakie znajdziemy na większości serwerów produkcyjnych i systemach CI/CD. Dzięki temu unifikujemy środowisko i eliminujemy wiele „magicznych” problemów.
Pierwsze uruchomienie – dlaczego to bywa trudne?
Może się wydawać, że stworzenie pustej aplikacji to banał. Jednak początkowe kroki mogą być zaskakująco złożone:
konflikt wersji node i npm,
błędna konfiguracja Tailwinda,
brakujące zależności lub nieudana instalacja paczek,
różnice między Windows a WSL, np. dostęp do plików lub system uprawnień,
problemy z działaniem serwera developerskiego (vite dev) w niestandardowej konfiguracji sieciowej.
Dlatego warto uzbroić się w cierpliwość i potraktować te trudności jako cenną lekcję środowiskową. Gdy już aplikacja się uruchomi, docenimy szybkość i wygodę, jaką zapewnia ten zestaw narzędzi.
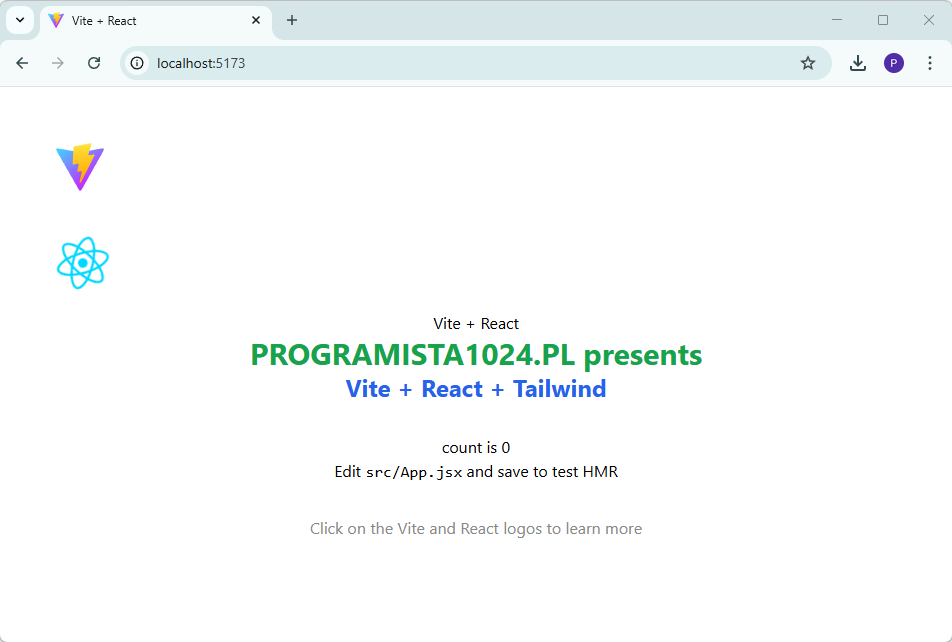
Terminal Ubuntu z uruchomionym serwerem developerskim Vite po wpisaniu polecenia npm run dev. Widoczny adres localhost:5173.Strona startowa aplikacji React z napisem PROGRAMISTA1024.PL presents Vite + React + Tailwind. Stylizacja za pomocą klas Tailwinda.
Na blogu programista1024.pl zwykle skupiamy się na kodowaniu, testowaniu i wdrażaniu, w końcu to nasz slogan: „testujemy, kodujemy, wdrażamy”. Ale zanim zaczniemy budować systemy, które działają w przeglądarce, komunikują się z bazą danych albo rozmawiają z innymi usługami warto zrozumieć, co tak naprawdę dzieje się pod spodem. A wszystko zaczyna się od… sieci.
Bo nawet najlepiej napisany kod nie zadziała, jeśli aplikacja nie potrafi nawiązać połączenia. Jeśli router nie działa, adres IP jest błędnie przypisany albo protokół nie został zrozumiany przez drugą stronę, użytkownik zobaczy tylko błąd. I choć z poziomu przeglądarki może to wyglądać jak czarna magia, dla technika informatyka to pierwszy sygnał, że trzeba sięgnąć głębiej – do podstaw sieci komputerowych.
Dlaczego warto się tego nauczyć?
To pierwszy krok w nauce o sieciach lokalnych (LAN), który będzie Ci towarzyszył przez całą edukację i karierę. To coś więcej niż materiał do zaliczenia na lekcji. To wiedza, która pomaga:
zrozumieć, jak naprawdę działa Internet i sieci lokalne,
rozwiązywać realne problemy techniczne (np. brak połączenia),
i przygotować się do konfiguracji, testów i wdrożeń, czyli tego, co robimy każdego dnia jako technicy, administratorzy i programiści.
Zaczynasz od prostych pojęć:
Co to jest sieć komputerowa?
Jakie są topologie?
Do czego służy router, a do czego switch?
Czym różni się skrętka od światłowodu?
To właśnie ten etap pozwoli Ci poczuć się pewnie, zanim przejdziesz do zaawansowanych konfiguracji, routingu, wirtualnych sieci i systemów opartych na mikroserwisach. Sieć to krwioobieg każdego projektu informatycznego, niezależnie od tego, czy tworzysz stronę, grę online czy aplikację chmurową.
Na koniec…
Nie lekceważ podstaw. Im lepiej je zrozumiesz teraz, tym mniej zaskoczy Cię później przy błędach połączeń, konfiguracji Firewalla czy debugowaniu aplikacji, która „działa u mnie, ale nie na serwerze”.
Ten temat to dopiero początek, ale solidny. I pamiętaj – programista, który rozumie sieci, to programista, który naprawdę wdraża. Innymi słowy znajomość sieci to fundament, który sprawia, że nie będziesz kodował „w ciemno”.
📌 O autorze: Autor wpisu jest absolwentem informatyki na politechnice oraz posiada wykształcenie pedagogiczne. W latach 2005-07 prowadził zajęcia z przedmiotów zawodowych na kierunku Technik Informatyk, dzieląc się swoją wiedzą zarówno z teorii, jak i praktyki zawodu. Dziś łączy doświadczenie nauczyciela i programisty, tworząc materiały edukacyjne z myślą o tych, którzy dopiero zaczynają swoją drogę w IT.
Docker to popularne narzędzie do uruchamiania aplikacji w izolowanych kontenerach. W przeciwieństwie do Dockera w systemie Windows, który wymaga dodatkowej warstwy wirtualizacji, na Linuksie działa bezpośrednio w systemie, co jest szybsze i stabilniejsze. Jeśli dotąd korzystałeś z Dockera w Windows, rozważ przesiadkę na Linux – praca z kontenerami będzie prostsza i bardziej efektywna. A oto krótki przewodnik po przydatnych poleceniach, które umożliwią zainstalowanie oraz sprawdzenie Dockera w Fedora Linux.
Instalacja Dockera i Docker Compose
Zainstaluj Dockera i narzędzia dodatkowe:
sudo dnf install moby-engine docker-compose
Uruchom i włącz usługę Dockera:
sudo systemctl enable --now docker
Powyższe polecenie spowoduje, że Docker zostanie uruchomiony już w bieżącej sesji, a także będzie uruchamiany automatycznie przy każdym starcie systemu.
Krótkie podsumowanie zainstalowanych pakietów:
moby-engine to open-source’owy silnik Dockera, rozwijany w ramach projektu Moby. W praktyce pakiet ten dostarcza ten sam silnik, na którym oparty jest Docker CE (Community Edition). Jest to główne narzędzie do uruchamiania, zatrzymywania i zarządzania kontenerami. Pozwala tworzyć środowiska uruchomieniowe dla aplikacji w odizolowanych kontenerach.
docker-compose jest dodatkowym narzędziem umożliwiającym definiowanie i uruchamianie wielu kontenerów jednocześnie, za pomocą jednego pliku docker-compose.yml. Ułatwia budowanie i uruchamianie złożonych aplikacji, które składają się z kilku współpracujących usług (np. serwer aplikacji, baza danych, cache).
Dodanie użytkownika do grupy docker
Aby używać Dockera bez sudo, należy dodać swojego użytkownika do grupy docker:
sudo usermod -aG docker $USER
Wyloguj się i zaloguj ponownie lub uruchom w terminalu:
newgrp docker
⚙️ Jak działa Linux? Usługa Dockera tworzy gniazdo /var/run/docker.sock, które należy do grupy docker. To gniazdo to interfejs komunikacyjny między klientem Docker a demonem dockerd. Dzięki temu tylko użytkownicy należący do grupy docker mają uprawnienia do zarządzania kontenerami bez sudo.
Test działania Dockera
Uruchom przykładowy kontener testowy:
docker run hello-world
Jeśli wszystko działa, zobaczysz komunikat zaczynający się od:
Hello from Docker! This message shows that your installation appears to be working correctly.
Zarządzanie kontenerami
Wyświetlenie listy działających kontenerów:
docker ps
Wyświetlenie listy wszystkich kontenerów (w tym zatrzymanych):
docker ps -a
Usunięcie zatrzymanych kontenerów:
docker container prune
Powyżej przedstawiliśmy podstawowe polecenia do wyświetlania i usuwania kontenerów. W kolejnym artykule opublikuję szczegółową tabelę z przykładami dodatkowych komend, takich jak zatrzymywanie i usuwanie kontenerów, wyświetlanie listy obrazów Dockera, przeglądanie logów oraz usuwanie niepotrzebnych obrazów. Te polecenia pozwolą Ci w pełni kontrolować i porządkować środowisko Dockera.
W tym artykule opisuję nietypowy, lecz wcale nie rzadki przypadek, z którym może zmierzyć się każdy twórca aplikacji webowych. Port 8080 domyślnie wykorzystywany przez wiele aplikacji Spring Boot był zajęty przez nieznaną usługę systemową. Źródłem problemu okazało się dodatkowe oprogramowanie zainstalowane „przy okazji” razem z narzędziem do zarządzania partycjami dysku.
Na konkretnym przykładzie pokażę, jak krok po kroku zdiagnozować takie sytuacje za pomocą wbudowanych narzędzi systemowych i PowerShella.
Choć opis dotyczy aplikacji Spring Boot uruchamianej w środowisku Eclipse, to również programiści korzystający z innych języków i frameworków takich jak Node.js, .NET czy Python znajdą tu uniwersalne wskazówki, pomocne w rozwiązywaniu problemów z konfliktem portów.
Przypadek został przeanalizowany na systemie Windows z pełnymi uprawnieniami administratora. Opisywane metody nie były testowane w systemach Linux ani macOS, w których mogą występować inne narzędzia oraz odmienna procedura rozwiązywania podobnych problemów.
Objawy
Po uruchomieniu aplikacji Spring Boot pojawił się błąd:
APPLICATION FAILED TO START Web server failed to start. Port 8080 was already in use.
To jasna wskazówka, że ktoś już korzysta z portu 8080. Wymagana była diagnoza, kto to robi i dlaczego.
Narzędzia diagnostyczne i komendy
Poniżej zestaw narzędzi systemowych i komend PowerShell/CMD użytych do analizy sytuacji.
1. Sprawdzenie, co nasłuchuje na porcie 8080
W terminalu wpisz następujące polecenie.
netstat -ano | findstr :8080
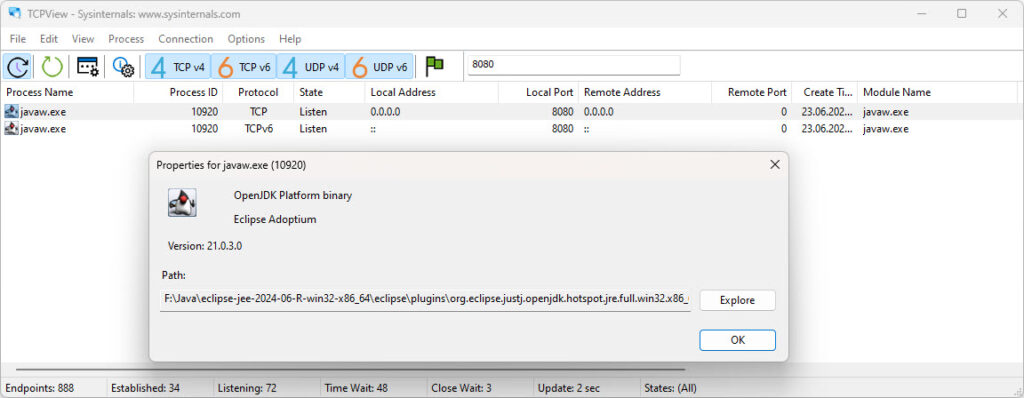
Ta komenda pozwala zidentyfikować, czy port jest aktualnie w użyciu i przez jaki proces (PID). W moim przypadku w konsoli wyświetliła się linia. Ostatnia wartość to identyfikator procesu.
TCP 0.0.0.0:8080 LISTENING 5184
2. Kto używa PID 5184?
Aby dowiedzieć się, jaki program odpowiada za dany PID, używamy komendy tasklist.
tasklist /FI "PID eq 5184"
Dla mojego przypadku wynik wskazywał na AgentService.exe, ale brak było dodatkowych informacji.
3. Identyfikacja lokalizacji procesu (z uprawnieniami administratora)
Wykonanie tej komendy pozwala sprawdzić dokładną ścieżkę do pliku wykonywalnego procesu.
Name : MTAgentService DisplayName : MTAgentService PathName : "C:\Program F...\MiniTool ShadowMaker\AgentService.exe" State : Running StartMode : Auto
Ustalenia
Usługa MTAgentService, zainstalowana wraz z MiniTool ShadowMaker PW Edition, blokowała port 8080. Co ciekawe, narzędzie to było zainstalowane tego samego dnia co MiniTool Partition Wizard, najprawdopodobniej jako komponent dodatkowy.
Sprawdzenie daty instalacji aplikacji
Aby ustalić, które programy zostały zainstalowane danego dnia (np. 23 lutego 2025 roku), można wykorzystać rejestr systemu Windows. Informacje o zainstalowanych aplikacjach przechowywane są w kluczach rejestru, z których możemy odczytać m.in. nazwę aplikacji (DisplayName) oraz datę instalacji (InstallDate).
Poniższe polecenie PowerShell pozwala przeszukać rejestr systemowy i wyświetlić aplikacje zainstalowane danego dnia:
W systemach 64-bitowych programy 32-bitowe instalowane są w osobnym obszarze rejestru (Wow6432Node). Jeśli chcesz mieć pełny obraz (aplikacje 64- i 32-bitowe), skorzystaj z poniższego skryptu:
Unikaj domyślnego portu 8080 w aplikacjach deweloperskich
Port 8080 to jeden z najczęściej wykorzystywanych portów przez aplikacje webowe i narzędzia firm trzecich (takie jak MiniTool ShadowMaker, IIS, serwery BI czy inne lokalne usługi). Jeśli tworzysz aplikację w Spring Boot, Node.js, React czy innym frameworku rozważ ustawienie alternatywnego portu, np. 8081, 5173, 3000 albo wybranego zgodnie z wewnętrznym standardem zespołu.
Standaryzacja i dokumentacja portów
W projektach zespołowych warto ustalić stałe porty dla różnych środowisk (np. 8081 dla developmentu, 8082 dla testów), by uniknąć konfliktów i ułatwić automatyzację. Przydatne jest także dodanie do repozytorium pliku .env.example lub dokumentacji z opisem portów i zmiennych środowiskowych używanych przez aplikację. W przypadku Spring Boot można odczytywać takie zmienne w application.properties, np. przez ${SPRING_PORT:8080}.
Jeśli chcesz zagłębić się w temat używania plików .env w aplikacjach Spring Boot, sprawdź ten przystępny artykuł:
Jeśli chcesz, aby Spring Boot dynamicznie dobrał wolny port, ustaw w application.properties:
server.port=0
Port zostanie wyświetlony w logu przy starcie aplikacji.
Sprawdzenie aktywnych portów po każdej instalacji oprogramowania
Po instalacji nowego programu sprawdź, które porty są aktualnie nasłuchiwane. Możesz użyć polecenia:
Get-NetTCPConnection -State Listen |
Group-Object LocalPort |
Sort-Object Name
Korzystaj z TCPView do szybkiej analizy portów
Graficzne narzędzie TCPView od Sysinternals to niezastąpione wsparcie w wykrywaniu konfliktów portów. Pozwala błyskawicznie zidentyfikować proces, usługę i lokalizację aplikacji nasłuchującej na danym porcie.
Jeśli preferujesz graficzne narzędzia diagnostyczne, użyj TCPView (arch. własne)
Ostrożność przy instalacji oprogramowania narzędziowego
Instalując narzędzia typu „partition manager”, „backup software” czy „BI agent”, wybieraj tryb instalacji niestandardowej (custom), aby wykluczyć dodatkowe komponenty. Wielu producentów instaluje przy okazji własne usługi systemowe, które mogą działać w tle i blokować kluczowe porty.
Przypadek korporacyjny
Ten przypadek dotyczył stacji roboczej z pełnymi prawami administratora. W środowisku korporacyjnym sytuacja jest trudniejsza:
Brak dostępu do zaawansowanych komend
Brak uprawnień do zatrzymywania usług
Konieczność zgłoszenia do helpdesku
W następnym wpisie zaproponuję podejście do tworzenia zgłoszenia serwisowego oraz przygotowania pakietu diagnostycznego do analizy problemów z portami, uruchamianiem aplikacji oraz konfliktem usług w firmowym systemie Windows.
Podsumowanie
To studium przypadku pokazuje, jak niepozorne narzędzie może skutecznie zablokować pracę nad aplikacją. Diagnoza i znajomość narzędzi systemowych (takich jak PowerShell, TCPView, netstat) są nieocenione w codziennej pracy deweloperskiej. Ten przypadek zostanie rozszerzony o scenariusz korporacyjny, by pomóc innym programistom i administratorom szybciej reagować na podobne problemy.
FAQ
Czy InstallDate zależy od języka i lokalizacji systemu?
to liczba całkowita reprezentująca datę w formacie YYYYMMDD (czyli RRRRMMDD, np. 20250223 oznacza 23 lutego 2025). Jest to techniczna wartość typu DWORD, a nie tekstowa reprezentacja daty, więc nie podlega lokalizacji, ustawieniom regionalnym ani formatom wyświetlania.
Dlaczego PowerShell może błędnie wkleić polecenie?
Kiedy kopiujesz dłuższy blok kodu do konsoli PowerShell bezpośrednio z przeglądarki, upewnij się, że całość wkleiła się poprawnie. Zdarza się, że kolejność linii może się odwrócić lub złamać (szczególnie w pętli foreach), co prowadzi do błędów takich jak:
Rozwiązanie: Wklej cały blok kodu najpierw do edytora tekstu (np. Notepad++ lub VS Code), a dopiero potem do PowerShella. Alternatywnie użyj terminala PowerShell ISE lub Windows Terminal, które lepiej radzą sobie z wieloliniowym kodem.
Masz podobny przypadek? Podziel się w komentarzu lub napisz do mnie na LinkedIn.
8 czerwca obchodzimy Dzień Informatyka – święto wszystkich, którzy każdego dnia budują i utrzymują cyfrowy świat: programistów, administratorów, testerów, inżynierów danych, specjalistów od bezpieczeństwa, devopsów, analityków, architektów systemów… lista jest długa.
To dobry moment, by zadać sobie pytanie: kim właściwie jest informatyk?
W potocznym rozumieniu to „osoba od komputerów”, często mylona z administratorem sieci lub kimś, kto naprawi drukarkę albo pomoże ci zalogować się do systemu. W rzeczywistości zakres kompetencji informatyków jest ogromny – od tworzenia algorytmów sztucznej inteligencji po projektowanie systemów informatycznych dla instytucji publicznych, od zarządzania bazami danych po budowanie aplikacji mobilnych.
Informatyka przeszła długą drogę od czasów, gdy informatyk kojarzył się głównie z „naprawiaczem komputerów”. Dziś to architekt cyfrowej transformacji, strateg biznesowy i kreator technologicznych rozwiązań, które kształtują przyszłość gospodarki.1
Ale czy „informatyk” to w ogóle zawód?
Tu sprawa robi się ciekawa. W oficjalnej klasyfikacji zawodów i specjalności (np. w polskim rozporządzeniu MRiPS) nie znajdziemy prostego wpisu „informatyk”2. Pojawiają się za to konkretne role: programista aplikacji, administrator baz danych, inżynier ds. sieci komputerowych, specjalista ds. bezpieczeństwa IT, analityk systemowy, itd.
Czy informatyk ponosi odpowiedzialność zawodową?
Choć nie wykonujemy zawodu regulowanego w sensie prawnym, nasza odpowiedzialność jest realna – i często ogromna. Od nas zależy bezpieczeństwo danych, stabilność systemów, czasami nawet zdrowie lub życie ludzi. To odpowiedzialność oparta nie tylko na przepisach, ale i na etyce zawodowej. Informatyk to nie tylko specjalista – to także powiernik zaufania społecznego, nawet jeśli nie widnieje to w żadnej ustawie.
Czego można życzyć informatykowi?
Z okazji Dnia Informatyka – dziękuję wszystkim, którzy współtworzą ten cyfrowy świat, zarówno zawodowo, jak i pasjonacko. Wasza praca ma znaczenie – często niewidoczne na pierwszy rzut oka, ale niezbędne w codziennym funkcjonowaniu świata.
Niech wasz kod będzie czysty, systemy stabilne, a deploy na produkcję bez niespodzianek!
A Ty – kim jesteś w świecie IT? Informatykiem? Programistą? Testerem? A może po prostu kimś, kto lubi rozwiązywać problemy?
Tak naprawdę klasyfikacja ulega częstym zmianom. W „Rozporządzeniu Ministra Rodziny, Pracy i Polityki Społecznej z dnia 12 września 2024 r. zmieniającym rozporządzenie w sprawie klasyfikacji zawodów i specjalności na potrzeby rynku pracy oraz zakresu jej stosowania” [Dz.U. 2024 poz. 1372] dodano wpis zawodu „Informatyk” o kodzie cyfrowym 251106. Rozporządzenie weszło w życie z dniem 1.01.2025, jednak na dzień pisania tego artykułu jest już uchylone przez „Ustawę z dnia 20 marca 2025 r. o rynku pracy i służbach zatrudnienia” [Dz.U. 2025 poz. 620], która obowiązuje od 1.06.2025. ↩︎
Zestaw justPi to kompletny pakiet, zawierający wszystkie niezbędne elementy do uruchomienia i użytkowania Raspberry Pi. Jest zaprojektowany z myślą o użytkownikach, którzy chcą szybko i łatwo rozpocząć pracę z tym popularnym mikrokomputerem. W tym filmie prezentujemy zestaw, którego sercem jest Raspberry Pi 4 Model B z 8GB RAM na płycie głównej. Oprócz mikrokomputera w pudełku są dodatkowe akcesoria, jak: obudowa, zasilacz, karta pamięci z wstępnie zainstalowanym systemem operacyjnym, kable HDMI i Ethernet, oraz niezbędne narzędzia i instrukcja obsługi.
Omówienie zestawu justPi Starter Kit z Raspberry Pi 4B
Tworzymy pierwszą wersję aplikacji wykorzystując edytor nano w linuxie. Poznajemy podstawowe konstrukcje języka. Poza tym dowiadujemy się, jak sprawdzić wersję Pythona w linuxie oraz jak uruchamiać napisane programy. To nie wszystko, bo kodowanie to nie jedyna umiejętność programisty. Nauczymy się tworzyć logikę programów przy pomocy narzędzi do rysowania schematów blokowych i diagramów UML. Poznamy też sposoby debugowania kodu i tworzenia automatycznych testów.
Pierwsza wersja „Pogodynki” zamiast „Hello, World!”
Linux jest doskonałym środowiskiem do nauki programowania w języku Python z wielu powodów. Jednym z nich jest łatwość instalacji narzędzi deweloperskich. System Linux jest wybierany również jako środowisko uruchomieniowe przez wiele firm. Dlatego nie trzeba długo tłumaczyć, że warto połączyć naukę programowania z obsługą samego systemu.
W tym artykule, krok po kroku pokażemy, w jaki sposób można przygotować środowisko deweloperskie w jednej z popularnych dystrybucji Linux Fedora.
1. Aktualizacja systemu
Pierwszym krokiem przed instalacją nowego oprogramowania w systemie Linux jest aktualizacja samego systemu operacyjnego. Jeśli aktualizacja systemu nie jest ustawiona jako proces automatyczny, należy tą czynność przeprowadzić ręcznie.
W poniższym przykładzie pracujemy na dystrybucji Fedora w wersji 39. W czasie tworzenia tego artykułu dostępna jest nowsza wersja Fedora Workstation 40, którą można pobrać ze strony http://fedoraproject.org.
Jeśli poważnie myślisz o programowaniu w systemie linux, powinieneś rozważyć wykonanie tego kroku. Dzięki temu uzyskasz dostęp do narzędzi deweloperskich – kompilatorów, debugerów, bibliotek źródłowych i narzędzi pomocniczych. Mogą być one użyteczne przy pracy z różnymi językami programowania, w tym także z Pythonem, szczególnie w kontekście integracji z kodem napisanym w C/C++.
Instalacja Development Tools w systemie Linux Fedora
3. Instalacja Pythona i menedżera pakietów pip
Większość popularnych dystrybucji Linuxa instaluje Pythona domyślnie, ponieważ jest on potrzebny do działania wielu narzędzi systemowych i skryptów. Tak jest na przykład w użytej w przykładzie dystrybucji Fedora Workstation. Jeśli jednak używasz dystrybucji, która preferuje minimalną instalację (np. Arch Linux, Gentoo), Python może nie być domyślnie zainstalowany, ale można go łatwo zainstalować przy użyciu odpowiedniego menedżera pakietów.
Na tym etapie możesz zacząć tworzyć programy w języku Python. W systemie Fedora Linux Workstation 39, który używam podczas pisania tego artykułu, jest już zainstalowany interpreter python3 w wersji 3.12.3 (data wydania 9. kwietnia 2024 r.). I chociaż w systemie nie mam menedżera pakietów pip, to już teraz zachęcam abyś wypróbował kod programu do generowania prognozy pogody. Opis tego programu oraz materiały pomocnicze znajdziesz na stronie Wybrane programy w języku Python.
Zachęcam Cię do wsparcia mnie przy tworzeniu tego artykułu. Kliknij na grafikę obok i postaw symboliczną kawę.
W tym artykule zajmiemy się przykładem fragmentu aplikacji korzystającej ze specyfikacji Java Persistence API w wersji 2.1. Jest to więc trochę spojrzenie na JPA sprzed rebrandingu. Obecna wersja 3.2.0 (Jakarta Persistence API) była wydana w maju 2024. Jeśli twoja aplikacja była tworzona w latach 2013-2018, jest duża szansa, że korzystała z JPA 2.1 i może wymagać unowocześniania do nowej wersji. Zmiany mogą obejmować nie tylko rebranding na Jakarta Persistence API, ale także mieć wpływ na sposób, w jaki twój kod jest zarządzany i wykonywany.
Opis biznesowy
Głównym celem projektu jest pokazanie, jak skonfigurować i używać starsze wersje bibliotek do implementacji operacji CRUD (Create, Read, Update, Delete) w aplikacjach opartych na JPA (Java Persistence API). Projekt demonstruje, jak radzić sobie z konfiguracją i zarządzaniem zależnościami w czasach, gdy popularne rozwiązania jak Spring nie były jeszcze powszechnie używane lub dostępne.
Kod projektu jest dostępny w repozytorium na GitHubie pod adresem java-jpa-demos. Jest to fragment większej aplikacji, który dotyczy operacji na bazie danych. Ten projekt jest szczególnie wartościowy dla programistów chcących zrozumieć, jak starsze aplikacje były budowane i konfigurowane, zwłaszcza bez użycia nowszych technologii, takich jak Spring Framework.
Informacje techniczne
W niniejszym przykładzie będziemy rozważać program wykorzystujący następujące biblioteki.
MySQL Connector Java, wersja 8.0.26, data wydania 19.07.2021
MySQL Connector/J w wersji 8.0.26 to sterownik JDBC dla MySQL, który umożliwia aplikacjom Java komunikację z bazą danych MySQL. Poniżej znajdziesz szczegółowe informacje o kompatybilności tej wersji z różnymi technologiami.
Java: MySQL Connector/J 8.0.26 jest kompatybilny z Java 8 i nowszymi wersjami, w tym Java 11 i Java 17. Jest zgodny z JDBC 4.2, co oznacza, że może wykorzystywać zaawansowane funkcje JDBC dostępne w nowszych wersjach Javy, takie jak np. „try-with-resources” oraz lepsze zarządzanie zasobami.
JPA (Java Persistence API): MySQL Connector/J działa z JPA 2.1 i nowszymi. Oznacza to, że może być używany z implementacjami JPA takimi jak EclipseLink czy Hibernate.
Hibernate ORM: MySQL Connector/J 8.0.26 jest kompatybilny z Hibernate 5.4 i nowszymi. Dzięki temu możesz korzystać z najnowszych funkcji oferowanych przez Hibernate, w tym wsparcia dla nowoczesnych typów danych i optymalizacji wydajności.
MySQL Server: MySQL Connector/J 8.0.26 jest kompatybilny z MySQL Server 5.7 i 8.0. Jest to ważne, ponieważ zapewnia wsparcie dla nowoczesnych funkcji i optymalizacji dostępnych w tych wersjach serwera MySQL.
TLS/SSL: Wersja 8.0.26 oferuje wsparcie dla najnowszych protokołów TLS, co zwiększa bezpieczeństwo połączeń z bazą danych.
Java Persistence API, Version 2.1, wersja 1.0.2.Final, data wydania 23.01.2018
Biblioteka hibernate-jpa-2.1-api w wersji 1.0.2.Final jest częścią specyfikacji JPA (Java Persistence API) i jest używana jako implementacja standardu JPA 2.1. Poniżej znajdziesz szczegółowe informacje o kompatybilności tej wersji z różnymi technologiami.
Java: Specyfikacja JPA 2.1 jest kompatybilna z wersjami Java SE 6, 7, 8. Wersje późniejsze niż Java 8 mogą również działać, ale należy zwrócić uwagę na kompatybilność całego stosu technologicznego.
Hibernate ORM: Hibernate 4.3.x i nowsze wersje są zgodne ze specyfikacją JPA 2.1. Zaleca się używanie co najmniej Hibernate 5.0 dla lepszej wydajności i wsparcia.
Serwery aplikacyjne: JPA 2.1 jest wspierana przez wiele popularnych serwerów aplikacyjnych, takich jak WildFly 8+, JBoss EAP 6.3+, GlassFish 4+, WebLogic 12c, WebSphere 8.5.5. WildFly 8 i późniejsze wersje mają wbudowaną obsługę JPA 2.1.
Frameworki webowe: Spring 4.x w pełni wspiera JPA 2.1. Użycie Spring Data JPA umożliwia łatwą integrację z Hibernate jako dostawcą JPA. Specyfikacja JPA 2.1 jest częścią Java EE 7.
Hibernate Core Relocation, wersja 5.5.7.Final, data wydania 25.08.2021
W niniejszym artykule pokazaliśmy, że aplikacje wykorzystujące starsze wersje bibliotek JPA nadal mogą działać poprawnie. Jednakże, należy mieć świadomość, że wraz z nowymi wersjami JPA 2.2 i 3.0 zostały wprowadzone nowe funkcje i usprawnienia, które mogą istotnie zwiększyć wydajność i elastyczność aplikacji. Przykładowo, JPA 2.2 wprowadził wsparcie dla nowych typów zapytań (np. derived queries, native queries) oraz usprawnienia w obszarze zarządzania transakcjami. Z kolei wersja 3.0, rozszerzyła możliwości integracji z nowoczesnymi technologiami i narzędziami. Przed przeprowadzeniem aktualizacji z JPA 2.1 należy przeanalizować zmiany wprowadzone w nowych wersjach bibliotek zależności oraz opracować odpowiednie testy integracyjne, aby upewnić się, że aplikacja po migracji będzie działać zgodnie z oczekiwaniami.